|
|
Assembler-Beispiel 3 |
|
|
Assembler-Beispiel 3 |
Ausgabe "Hello World" 10 mal auf den Bildschirm
Das hatten wir schon!
Nun soll die Ausgabe verzögert werden, etwa so:

Nach jeder Ausgabe soll eine Wartezeit von etwa einer Sekunde erfolgen.
Um solche Wartezeiten zu erzeugen, gibt es mehrere Möglichkeiten.
Die einfachste, und die wollen wir nutzen, ist, indem man irgendetwas den Prozessor
ausführen läßt, was dann etwa eine Sekunde dauert.
Ein Befehl wird dafür sicher nicht ausreichend sein, man muss den sicher mehrfach
in einer Schleife ausführen lassen.
|
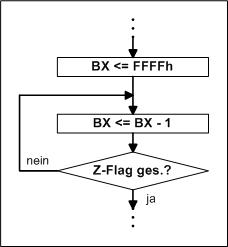
Wie bereits im Beispiel 2 bearbeitet wurde, ist nun wieder ein Register mit einem
Wert zu füllen und bis auf Null runterzuzählen. Wir nehmen diesmal ein 16-Bit Register, dann können wir die Schleife 65536 mal durchlaufen. Diese Schleife soll nicht weiter als die Reduzierung der Laufgröße mit dem SUB-Befehl durchführen! |
|

|
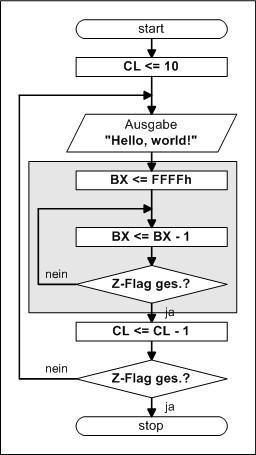
Diese Schleife wird entsprechend dem Beispiel 2 hinter die Ausgabe gesetzt. Nach jeder Ausgabe wird zunächst das Register auf den maximalen Wert FFFFh (alles 1) gesetzt. Dazu können wir ein weiteres Register nutzen, die Anzahl der Ausgaben kommen ins CL-Register, für die Verzögerung nutzen wir das BX-Register. Wollen wir den Loop-Befehl nutzen, müssen wir CX verwenden!
Nach Anwendung des Assemblers und des Linkers auf dieses Programm kann das Progamm
gestartet werden - und was stellen wir fest, es verzögert da nichts!
Nein, es ist schon ok. |
Damit zeigt sich auch gleich das Problem dieser Art der Bearbeitung der Verzögerung,
denn führt man dieses Programm auf einem anderen Rechner mit anderer Taktfrequenz aus,
stimmen die Zeiten nicht mehr!
Dieses Problem kann man nur mit einer Timer-Programmierung realisieren - das braucht
aber wieder viel mehr Wissen!
|
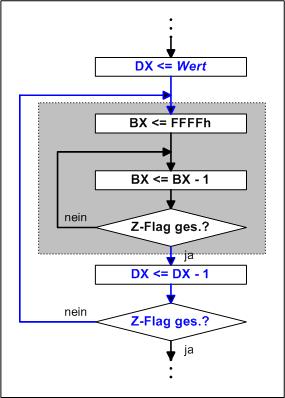
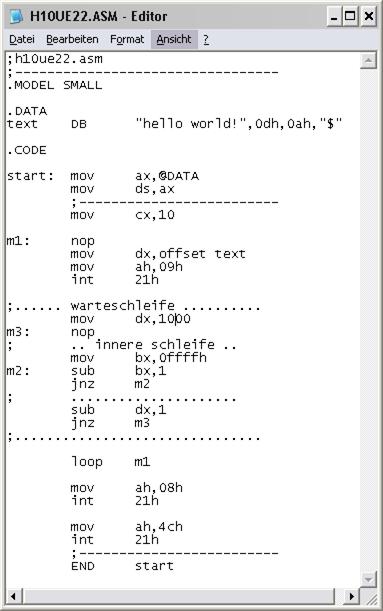
Wir geben uns mit dieser Methode zufrieden, aber die Verzögerung ist noch zu klein. Man sieht sofort, dass diese Schleife 1000 mal geschrieben werden muss, dass ist unmöglich. 1000 mal erreicht man aber auch, indem die Schleife in eine weitere Schleife gesteckt wird, die 1000 mal durchlaufen wird, das entspricht in etwa einer Multiplikation. |
|
|
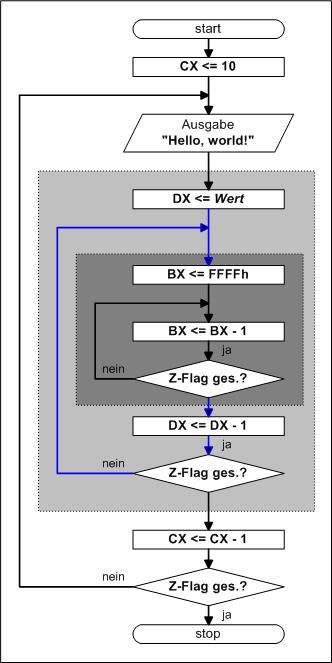
Nun haben wir es mit 3 geschachtelten Schleifen zu tun! Und das Problem könnten unsere Laufgrößen, die Register, sein. Das Register AX sollte man nicht dazu nutzen, dieses Register wird von vielen Befehlen gebraucht, auch vom Interrupt, z.B. für die Text-Ausgabe. Die äußere Schleife nutzt das CX-Register (CL würde auch reichen, aber wenn wir wieder den LOOP-Befehl verwenden wollen, wird CX gebraucht. Ganz innen wird BX genutzt und darüber dann DX. Letzteres könnte ein Problem ergeben, da ja auch für die Ausgabe DX gebraucht wird. Das kann man machen, da beide Aktionen völlig getrennt durchgeführt und auch abgeschlossen werden. Das Programm wurde so bearbeitet und der Start zeigt etwas Verzögerung, aber immer noch nicht ausreichend, Erst wenn der Wert auf 10000 gesetzt wird, gibt es eine sichtbare Verzögerung - der Rechner ist doch etwas schneller, auch wenn er schon einige Jahre alt ist. |
Nun wollen wir an diesem Beispiel eine weitere Leistung des Prozessors beschreiben.
Es wird bei größeren Programmen sicher so sein, dass die inneren Register des
Prozessors nicht ausreichen. Die Lösung ist dann wie beim kleinen Prozessor "ERNA",
dass man Werte im Hauptspeicher ablegen muss. Das geht relativ leicht und mit
unterschiedlichen Methoden.
Ein weiteres Problem ist, dass wir die inneren Schleifen genau wie die äußere mit
dem LOOP-Befehl realisieren wollen. Das geht nur, indem wir die momentanen Werte
vor Aufruf der neuen Schleife retten, also in den Hauptspeicher transportieren. Ist
diese Schleife beendet, müssen wir den geretteten Wert wieder zurückholen, damit die
äußere Schleife ordnungsgemäß fortgesetzt wird. Leider ist dieser Aufwand notwendig,
da der LOOP-Befehl nur mit dem CX-Register arbeitet!
Für solche Aufgaben nutzt man eine weitere Leistung, eigentlich Hardware des
Prozessors, den
Stack

|
Stack kann eine Hardware, ein Prinzip, oder auch eine Datenstruktur und vieles mehr
sein. Stack ist eine Einheit, die mehrere Werte Speichern kann, jedoch können nur an einer Stelle Werte in die Einheit gespeichert und auch nur von dort gelesen werden. Damit die Werte intern nicht verloren gehen, wird intern umgespeichert, z.B. sind 2 Ebenen belegt und es kommt ein dritter Wert, dann wird der Wert der Ebene 1 nach Ebene 2, danach Ebene 0 nach Ebene 1 geschoben. Nun kann der neue Wert in Ebene 0 gespeichert werden. Will man lesen, kann nun immer der zuletzt eingespeicherte Wert gelesen werden. Das entspricht dem Prinzip: Das erscheint zunächst unsinnig, es entspricht aber exakt einigen Programmstrukturen und läßt diese erst zu! Wurde der Wert gelesen, muss intern wieder umgespeichert werden. Das Einspeicher wird mit PUSH, das Lesen mit POP beschrieben. Der Assembler verwendet diese Bezeichnung auch gleich als Befehl, da wird das Umspeichern eben auch gleich mitorganisiert. Datenstrukturen verwenden auch noch "top", lesen der Ebene 0, aber nicht umspeichern, das gibt es nicht als Befehl. |
Das Prinzip ist gut, es hat nur einen großen Nachteil.
Wenn wir einen Stack mit 1000 Plätzen haben, müßte bei der Nutzung des Stacks bei der
Einspeicherung eines Wertes 1000 mal (genauer 999 mal) umgespeichert werden!
Damit ist eine schnelle Nutzung des Stacks hinfällig. Aber ein Ingenieur der
Informatik wäre kein Ingenieur, wenn ihm nicht was Besseres einfiele!
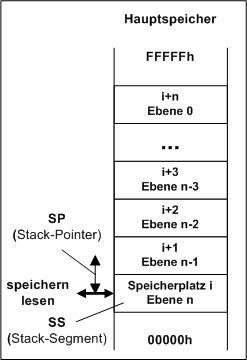
Beim 8086 gibt es deshalb die Anfangsadresse eines Stacksementes mit SS zu vereinbaren
und auch mit SP (Stackpointer) einen speziellen Zeiger in diesem Segment -
wie funktioniert der Stack nun?
|
|
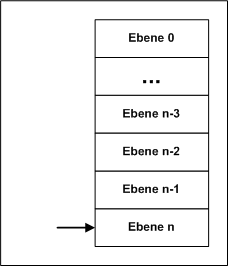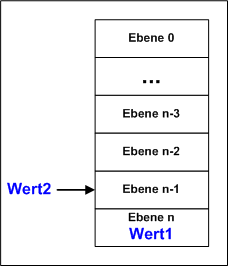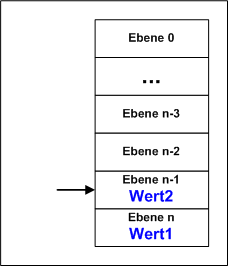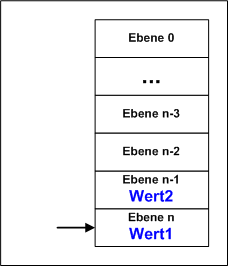
Das Verfahren ist eigentlich genial. Der Stack wird im Hauptspeicher an sinnvoller Stelle angelegt, es gibt keine extra Hardware wie z.B. für den Cache! SP ist nach der Vereinbarung Null und zeigt genau auf die Anfangsadresse des Stacksegmentes. Wird nun ein Wert in den Stack gespeichert, landet er auf dieser Adresse und der SP wird um 1 erhöht. Der nächste Wert wird nun auf SS + 1 gespeichert, der SP auf 2 erhöht. Beim Lesen muss nach diesem Prinzip zuerst der SP um 1 reduzier werden, dann kann gelesen werden. Das Prinzip kann auch genau anders funktionieren, indem beim Speichern erst der SP erhöht wird und dann gespeichert. Beim Lesen muss nach dem Lesen SP um 1 reduziert werden - beide Varianten sind gleichwertig. So wird jegliches Umspeichern im Stack vermieden, nur SP muss immer um 1 verändert werden - der Stack wird so doch sehr schnell!
Noch ein Hinweis:
|
Zu beachten ist, dass der Stack nicht nur zum schnellen retten von Werten genutzt wird, auch beim Aufruf von Unterprogrammen landen hier Werte (Adressen), gleichfalls auch bei Nutzung von Interrupten und auch die Parameter werden über den Stack übergeben - man sollte deshalb den Stack nur mit den vorgesehenen Befehlen nutzen (PUSH, POP), eine Veränderung des SP ist auch möglich, was man aber nur den Profis überlassen sollte, führt sonst meist zum Abbruch des Programms!
Damit können wir nun in einem Programm z.B. alle Schleifen mit dem LOOP-Befehl realisieren.
|
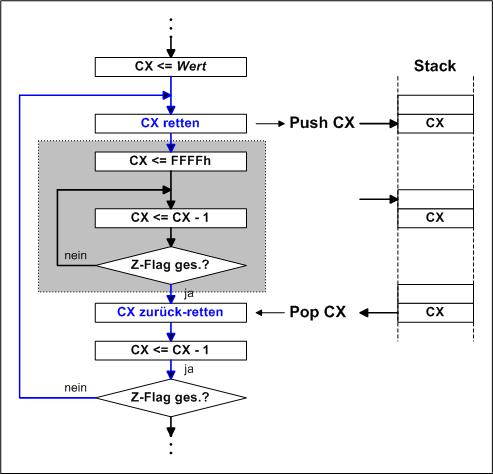
Links im Bild ist das Prinzip dargestellt. Im Register CX wird der Endwert für die erste (äußere) Schleife vereinbart. Nun soll die innere Schleife begonnen werden. Würde nun CX einfach neu beschrieben, ist der alte Wert verloren, also muss er erst gerettet werden, dazu nun der Befehl PUSH CX. Nun kann ohne Probleme die inneren Schleife (grau hinterlegt) bearbeitet werden. Ist diese beendet kann man nicht sofort die äußere Schleife runterzählen, erst muss der Wert aus dem Stack geholt und nach CX gespeichert werden, das übernimmt der Befehl POP CX. Ist diese Schleife noch nicht zu Ende erfolgt ein Sprung vors Retten und es beginnt von Neuem. |
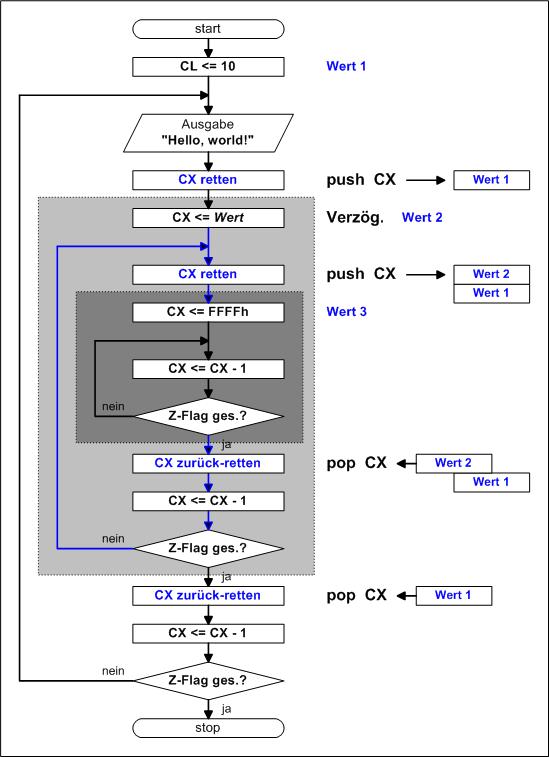
Und so sieht dann das komplette Programm aus:
|
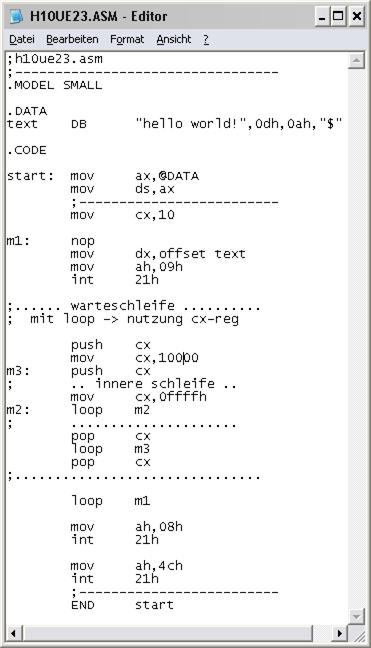
|
Zubeachten ist, dass im PAP für die 10 Durchläufe nur CL vereibart wurde, das ist ok.
Aber in den Stack kann man mit PUSH nur 16Bit transportieren, also CX. Das kann nun
ein Problem werden, denn wir wissen ja nicht, was auf CH stand! Das Programm könnte
anders ablaufen als erwartet.
Besser ist, man vereinbart CX = 10, dann wird auch CH exakt beschrieben, in diesem
Fall mit 00h (im Programm wurde das so durchgeführt)!
Und auf noch ein Problem soll aufmerksam gemacht werden!
Wir arbeiten zwar mit dem Stack (Nutzung PUSH und POP) haben aber kein Stacksegment vereinbart!
Der Linker schreibt deshalb eine Warnung aus. Das Programm funktioniert dennoch?
Der Stack wird offensichtlich in diesem Fall am letzten Ende des Codesegments angelegt, das
Programm und der Stack wachsen aufeinander zu. Für unsere kleinen Programme bereitet
das keine Probleme, wird der Stack jedoch intensiv genutzt, kann er in den Programmteil reichen
und speichert dort Werte ab, die das Programm als Befehl interpretiert -
in der Regel wird dadurch das Programm fehlerhaft beendet!
Kommt hingegen noch etwas Sinnvolles heraus, bemerkt man das Problem kaum, das ist sehr übel!
Um das zu Vermeiden sollte die Assembler-Direktive zur Vereinbarung eines Stack-Segmentes
genutzt werden. Wir schreiben gleich in die nächste Zeile hinter "MODEL SMALL":
.STACK 256
Damit wird ein Stack mit 256 Ebenen vereinbart (das ist ein empfohlener Wert), ohne Angabe wird
ein 1K Segment vereinbart.
Und noch eine letzte Bemerkung zum Stack.
Es gibt keinen Kennung im Stack, woher der Wert kam - logisch, also ist nicht zwangsweise vorgeschrieben
den Wert auch wieder dahin zurück zu speichern, z.B. wurden BX und CX in den Stack gelegt:
PUSH BX
PUSH CX
Irgendwann werden sie wieder zurück geholt:
POP BX
POP CX
Es wird der zuletzt abgelegte Wert auf BX und der davor auf CX gespeichert, das bedeutet aber,
dass nun CX den Wert von BX und BX von CX hat, wir haben die Inhalte von BX und CX getauscht -
kann ja sein, dass es so soll!?
Im Beispiel 4 wollen wir uns mit Unterprogrammen des Assembler-Systems beschäftigen.
|
|
zurück zur Start-Seite (Beispiele) / weiter Beispiel 4 |
|
|
|
zurück zur Start-Seite |