|
|
Berechnung der Speicheradressen |
|
|
Berechnung der Speicheradressen |
Auch beim 8Bit Prozessor Z80 wurde ähnlich verfahren, auch hier wurden 2Byte zur
Festlegung der Speicheradresse verwendet. Damit stehen 16Bit zur Berechnung der
Adresse zur Verfügung,
das sind 65536 Möglichkeiten.
In der Rechentechnik ist 210 = 1024, dafür wurde die Bezeichnung K (nicht
Kilo! - Ka) festgelegt.
Teilt man nun 65536 durch 1024 kommt genau 64 heraus, wir haben also 64KByte zur
Speicherung von Werten zur Verfügung.
Die logische Fortführung beim 8086 wäre, wenn nun wieder 2 mal 16Bit zur Adressierung, also
32Bit benutzt würden - das ist leider nicht so.
Es wird eine 20Bit Adresse benutzt damit also 220 = 1048567.
Teilt man diesen Wert wieder durch 1024, erhält man 1024, wir haben somit 1M
adressierbaren Speicherraum.
|
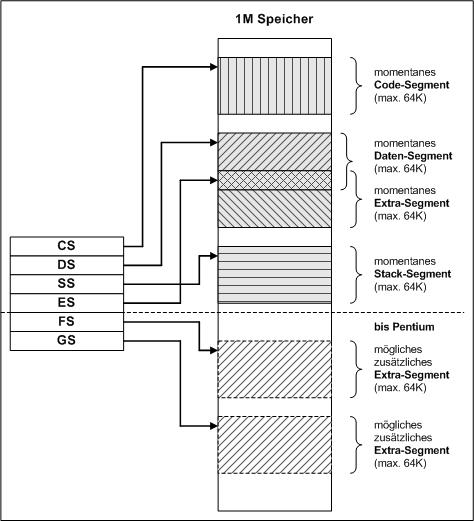
Wie erhält man nun ein 20Bit Adresse? 2 Byte reichen nicht, nimmt man 3 Byte kann man 24Bit zur Adresse benutzen, verschenkt aber, da nur 20 möglich sind, 4 Bit. INTEL ging einen anderen Weg. Man definiert Segmente, in diesen wird mit 16 Bit adressiert (also 64K), das Segmant kann aber relativ frei beliebig in den Speicher eingeordnet werden. Das geschieht indem man dem Segment eine "Basisadresse" gibt und die ist 20Bit groß. Die Festlegung dieser Basisadresse ist ganz einfach, der im Segmentspeicher stehende Wert (Adresse) wird einfach 4 mal nach links geschoben, also mit 16 multipliziert. Damit kann also die maxile Adresse 64K * 16 = 1024K = 1M sein. Damit ist noch nicht viel erreicht, denn wir bewegen uns ab Basisadresse maximal in einem 64K Adressraum. INTEL musste also weitere Segmentadressen spendieren, um den weiteren Speicherbereich nutzen zu können. So entstanden also die 4 Segmentregister: CS, DS, SS und ES. Die Aussagen gelten für ein Programm. Durch weitere Programme, wie z.B. spezielle Unterprogramme, die ja auch über die 4 Segmentadressen verfügen können, kriegt man den Speicher dann voll. Mit 16 Segmenten wäre der Speicher komplett ausgelastet. Aber es gibt auch die Möglichkeit Segmente überlappend zu betreiben, grob gesehen, sind das die Anfänge von "Shared Memory". Natürlich muss man aber auch wissen, dass der Assembler diese Problematik verwalten muss, es muss entsprechende Organisationsbefehle geben! Und der Assemblerprogrammierer muss festlegen, wo die Segmente liegen sollen. Die Beschreibung nennt neue Begriffe, die zu entsprechender Zeit noch geklärt werden müssen, wie z.B. Stack-Segment. Damit muss man wissen was ein Stack ist und wie er in diesem System funktioniert. Man kann aber sofort schon feststellen, dass das Programm wohl im Codesegment und die Daten zum Programm im Datensegment gespeichert werden, das entspricht der Harvard-Architektur von Rechnern. Wir werden aber noch sehen, dass wir diese Struktur auch wieder ändern können. |
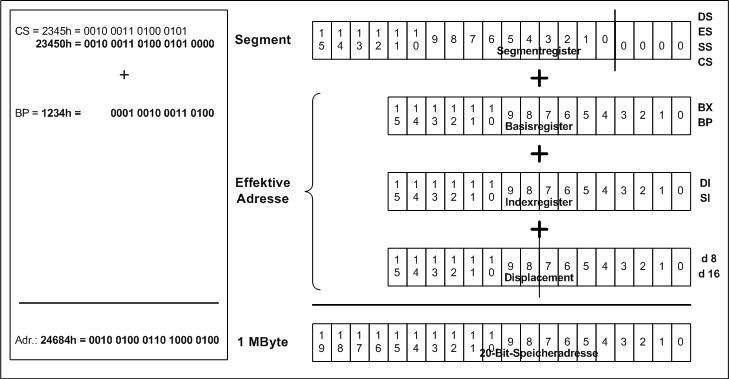
Es wurde kurz gezeigt, wie die reale Adresse im Speicher entsteht, aber neben dem
BP (Base-Pointer) kann das System noch weitere Register zur Adressenberechnung
hinzu ziehen. mit den Indexregistern sind dann schon Array ähnliche Strukturen
möglich.
Um also die reale Adresse zu ermitteln bedarf es nun schon einiger Operationen,
das kann nur ein Rechenwerk, welches über Additions- und Verschiebemöglichkeiten
verfügt, das ist das Adresswerk im BIU.
Im Folgenden ist noch einmal die Adressenberechnung schematisch dargestellt:
Um ganz einfache Programme zu schreiben, sollte man sich zuvor mit dem
Interrupt-System
beschäftigen, über den Weg kann man auf System-Funktionen zugreifen.
Eine z.B. ist die Textausgabe.
Man kommt auch ohne aus, dass ist jedoch aufwendiger als das Wissen zur Nutzung der
Interrupte zu lernen!
|
|
zurück zur Start-Seite / weiter Interrupt-System |
|